● 2003.10.28(火)01 Bee on the web パーソナル検索エンジンの実験
何人かの人には話をしていたり、また勘がいい人は多分うちのサイトの種々の実験から感づいていたと思うのですが、9月ぐらいからBeeにHTTPサーバー機能をつける実験をしていました。
9月中ぐらいに一通りの機能は付いていたのですが、i-appliのお仕事が忙しくてインターフェースの実装&実験が切れ切れにしか進んでいませんでした。どうにか、月曜の朝にインターフェースが一通り実装できたので、少し公開実験をしてみようと思います。
でもまあ、まだまだ落ちたり、応答が鈍かったり色々とあると思いますが。
さて、今回のBeeへのHTTPサーバー機能の実装ですが、何をやりたかったのかと言うと、「パーソナル検索エンジン(外部公開用)」を作りたかったのです。
個人的には、Web技術で現在最も重要なのは、blogではなく検索エンジンだと思っています。しかし、検索エンジンはGoogleなどの大手検索エンジンがその技術の中心で、個人が遊びで運用するようなものではありません。
「それじゃまあ、Beeの上でやってしまえ」というわけです。
元々Beeのプロジェクトには、「インターネットで使われる様々な技術を、Beeというプラットフォーム上で色々とコラボレーションして遊ぶ」というコンセプトがあります。そして、最終的な目標地点まで、いくつかの技術的導入フェイズに分けて、逐次機能を導入していく予定になっています。Beeプロジェクトは、数年がかりで行なう予定のかなり長い実験的プロジェクトだったりします。
Bee1.10では、いくつかの技術を組み合わせて「Webのリアルタイム検索」という概念を作って遊んでいました。
Bee1.10では、公開後に「スケジュール機能」などいくつかの機能を実装していましたが、これは1.20で実装予定だった「パーソナル検索エンジン・サーバー」という概念で遊ぶための下準備でした。
というわけで、今回1.20向けにHTTPサーバー機能を実装しました。
とはいえ、いきなり全ての機能をWeb対応として実装できるわけではありません(私の負担もありますので)。そこでまずは、「キャッシュの閲覧」と「キャッシュの検索」の機能を実装してみました。
つまり何ができるかと言うと、「スケジュール機能による自動巡回DL」や「DL&検索」でダウンロードしたファイルを、「Web上から検索できるようになる」というわけです。
この「パーソナル検索エンジン」の概念ですが、導入にはいくつかの障害がありました。その1つが、「IPさらし」と「Windows落ち」です。
個人でHTTPサーバーを公開した場合に問題になるのが、「IPをさらすのが嫌」ということと、「IPが接続の度にプロバイダーから自動で割り振られる(変わってしまう)」ことと、「Windowsはよく落ちる」ということです。
つまりどういうことかと言うと、http://xxx.xxx.xxx.xxx/というIP直指定のURLを公開しても、接続が切れる度にIPが変わってしまうし、それを毎回報告するのも面倒ということです。IPを公開すると攻撃されそうで怖いという人も多いと思いますし。
そこで今回は、それを避けるために、自動URLマウントの処理を入れることにしました(URLマウントに関しては、URLマウントの実験を参考にして下さい)。
Beeの設定ウィンドウで「URLマウントを有効」にしておくと、10分に一度、ローカルマシンのIPを自動的にCGIに通知するようになります。もちろん、手動ですぐ送ることもできます。
これで、あたかも自分のサイトの1機能のように、ローカル上で動いているBeeを、そのサイト上にマウントできるようになります。
というわけで、少し(数日?)HTTPサーバーの公開実験をして見ようかと思います。
ただし、マシンが貧弱なので、それは覚悟して下さい。Google様のように、何台もの強力なマシンが動いているわけではなく、メモリもCPUも貧弱なノートパソコンが1台で頑張っていますので。
検索速度も期待しては駄目です。Windows上で、300件以上、合計数MBの、文字コードがばらばらの文書を、文字コードを変換しながら全文検索するのです。過大な期待は禁物です。
公開実験前に、1人で実験したら30秒ぐらいかかりました。多分、それぐらいは少なくともかかると思います。ご理解下さい。
検索・閲覧可能なキャッシュに関しては、私がよく見るサイトいくつかのデータをDLしておきました。この設定で毎日巡回させれば、時系列の過去ログを閲覧・検索できるWebArchiveがすぐできます。
URLは、下記の通りになります。落ちていたらお慰み。まあ、マシンが貧弱ですし、プログラムも実験段階ですし。……気付いたら復旧します。
(リンク削除)
(実験サイトなので直リンは避けて頂けると有り難いです)
セキュリティホールや謎の挙動など発見されましたら、メールでお知らせ下さい(webmaster@crocro.com)。感想・要望などがある場合にも、同メール宛てでよろしくお願いします。要望関係は、1.20では反映できないと思うので、1.201以降の対応になるとは思います。
そんなわけで、数日実験をしますので、お付き合い頂ければと思います。
以下、今回の実験の設定などの導入手順です。
1.20正式公開後、遊んでみたい方は参考にして下さい(1~3まではバージョン1.1x台で既に実装されている機能です)。
● 1.設定の追加
ニュースサイトのトップページだけをDLするための新しい設定を作ります。メニューの「設定」で「設定ウィンドウ」を開き、「DL&検索 設定」を追加します。
※ 「リンク深度」を「2」にすれば、リンク先もまとめてDL可能です。ただ、深度2にすると、企業サイトのページとかも片っ端から集めてしまうので、今回の実験では深度1にしています。まあ、ミラーじゃなくて、あくまでキャッシュということを主張する気ですが :-P

● 2.IEのお気に入りの取り込み
Beeは起動時にIEのお気に入りを自動で取り込みます(JavaなのにWin依存……)。
「IEお気に入り」で、「このフォルダ以下を全て開く」を選択すれば、そのフォルダ以下のリンクを全て「DLリスト」に追加できます。これで巡回先を取り込みます。ここら辺のインターフェースは、タブブラウザのお気に入りに近い感覚です。
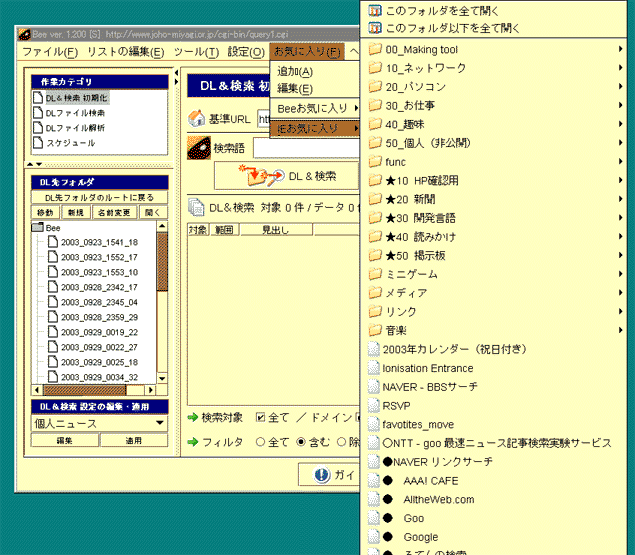
取り込みました。

DLリストと設定は、お気に入りに「追加」で、「Beeお気に入り」として、1つのファイルにパッケージ化することができます。毎回同じDLや検索をする場合に重宝します。

● 3.スケジュールの設定
作業カテゴリから「スケジュール」を選び、定期巡回設定を行ないます。
右クリックから、「新規スケジュール」を選びます。

先ほど「Beeお気に入り」に追加した設定をリストから選べます。後は、そのスケジュールの「有効」にチェックを入れ、巡回する時間を設定すればスケジュールの設定は終了です。設定した時間に、DLリストの自動DLを実行します。

● 4.HTTPサーバーの設定
メニューの「設定」で「設定ウィンドウ」を開きます。「設定ウィンドウ」で「HTTPサーバー」を選択します。
今の所は、以下の画面のような機能がついています。そのうち充実していくでしょう。
※ 「現在のIP」は自動で取得されます。

サーバーにアクセスすると、以下のような画面が表示されます。この画面はテンプレートを書き換えることで、カスタマイズ可能です。ニュース・コレクターと同じようなテンプレートになっています。
※ 「[+]」をクリックすると、そのフォルダの中身を一覧表示します。

Beeの「パーソナル検索エンジン・サーバー」の導入はこんな感じです。個人的には割と簡単だと思うのですが、普通の人はそうではないかもしれません。まあ、えてしてそういうものですし(T_T
というわけで、個人的探求心を満たす側面の強いBeeには、今後も世間の流行とは無関係に色々と実験的機能がついていくと思います。
こんな道楽みたいな実験ばかりやっているので、会社が大きくならないんだとか突っ込まれそうですが(汗)
まずは、実験を早く終了してBee1.20を公開したいと思います。あまり長い間バージョンアップしないと、ユーザーの方から石を投げられそうなので。バグFIXもかなりしているし(>_<
そんなわけで、今後も長い目でお付き合い頂ければと思います。よろしくお願いします。





