おすすめ

自作の本やゲーム他を販売

便利なWebアプリが多数
電書マンガ無料
Webマンガ
ゲームブック
闇の聖杯の儀式 電書のゲームブック
ゲーム
Little Land War... Win向けSRPG
Little Bit War Switch向け高速RTS
TinyWar... 1面数分の8bit風RTS
EX リバーシ 変形盤面、盤面多数
コミカライズ
同人活動
同人誌公開
no link
2010年03月30日 17:59:17
1つ前の記事:[EX リバーシ] 「ウサギ」ステージ
1つ後の記事:創活ノート 第14話「本の電子化」
今年の1月から3月にかけて、ScanSnapと断裁機を使って、本の電子化を行いました。
スキャンしたページ数は18万7174ページ。電子化した本や冊子、書類などの点数は900点です。
1点あたりのページ数は208ページなので、ほぼ900冊の本をスキャンしたと言ってよいでしょう。
かけた日数は48日。仕事をしながらの作業でしたので、正確には何時間か分かりません。
この作業ですが、最初の頃と最後の頃では、その効率が圧倒的に違っていました。
そこで、この経験を通して、最短で作業を進められる方法を、マニュアル化しておこうと思います。
同じように本の電子化をする人が、一から方法を模索するのは馬鹿らしいですので。
今回の一件を、マンガでも書きました。そちらは下記を参考にしてください。
□創活ノート 第14話「本の電子化」
https://codezine.jp/article/detail/4963
● 用意する道具
用意する道具ですが、以下のものを準備しました。最初の2つだけ購入しています。残りは、部屋にあったものを、そのまま利用しています。
・ドキュメント・スキャナ「FUJITSU ScanSnap S1500 FI-S1500」(Amazon価格:¥37,300)
・手動断裁機「プラス 断裁機 裁断幅A4 PK-513L 26-106」(Amazon価格:¥31,730)
・ディスク・カッター「ディスクカッター・ライト DC-100」(Amazon価格:¥2,436)
・カッター「L型カッター L-550P L-550P」(Amazon価格:¥326)
・カッター台
・金定規
● 道具についての解説1
○ ドキュメント・スキャナ
これがないと始まりません。本をスキャンして電子化してくれます。使い方や設定の詳細は後述します。
○ 手動断裁機
高価なものを買いましたが、中国製の安いものでも十分だと思います。少々斜めに裁断されても、ScanSnapで補正されますので。
あと、手動断裁機は、替えの刃が高価です。替えの刃の値段(15,000円)だけで、中国製の安い断裁機が買えます。そういう意味でも、安いもので済ましてもよいと思います。
○ ディスク・カッター
表紙をカットするのに使いました。普通のカッターで代用しても構いません。家にあったので、便利に使いました。
○ カッター
割と大きめの物を使っています。なぜならば、カッターは背表紙の解体用に使うからです。なので、小さいカッターだと怪我をします。大きめの、しっかりと握れるカッターがよいです。
○ カッター台
上述の、背表紙の解体の時に利用します。
○ 金定規
上述の、背表紙の解体の時に利用します。
ただし、慣れてくると、定規なしで、背表紙をきれいに解体できるようになるので、なくてもよいです。
● 道具についての解説2
本の電子化の記事でよく紹介されているけど、実際には使わなかったものです。
○ グルーガン
熱で接着剤を溶かして、背表紙をはがしやすくするためのものです。なくても困りません。
本のページの横幅を揃えたいという几帳面な人は、あった方がよいかもしれません。でも、電子化すると、そういったことは気にならないので必要ないです。
また、解体した本を再度修復するつもりがあれば必要だと思います。そういった目的がなければ、この道具は必要ありません。
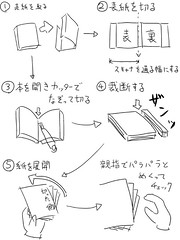
● 本の解体の仕方1(文庫、平綴じ本)
本は、効率よく、かつ、スキャンしやすいように解体するのがポイントです。
以下、その手順を書きます。本の中のハガキや広告は、あらかじめ除いておいてください。
1.表紙を取ります。
2.表紙を、表表紙と背表紙の間で、ディスクカッターでカットします。大型の本は、表紙の耳の部分もディスクカッターでカットします。
3【本の分割】.本の厚さが、断裁機を通らない場合は、以下の方法で本を分割します。
3−1.床にカッター台を置きます。
3−2.本を割って開きます。
3−3.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意が必要です。
3−4.紐がある場合は、背表紙側に引っ張って、取り除きます。(そのまま残すと、細かな糸くずになり、スキャナの内部に散らばってしまいます)
4.本を、断裁機で、背表紙側を数ミリ裁断します。
5【ページの確認作業】.ページが正しく断裁されているかの確認作業を行います。
5−1.切った側とは逆の位置を持ち、扇状に紙を広げます。
5−2.変なしなり方をしている場所があれば、糊でページがくっついているので、ページとページを手で切り離します。
5−3.扇状になった場所の上を指でなぞり、硬い部分があれば、糊でページがくっついているので、ページとページを手で切り離します。
5−4.何度かこの作業を行い、くっついている部分がなければ確認作業終了です。
5−5.大切な本の場合は、指で1枚ずつ分離して、きちんと離れているか確認します。
○ 【本の分割】についての補足
最初のうちは、金定規を当てた方がよいと思います。慣れれば、金定規なしでも、簡単に切り離せるようになります。
また、本によっては、数ページずつ中綴じされていて、それが糊でくっついています。そのため、開くページによって、切り離しやすさが違います。
本にもよりますが、糊が少ない場合は、糊だけでくっついているページの境目を狙うと切りやすいです。逆に糊が多い場合は、そこは避けた方がよいです。
どちらにしろ、あまり強くカッターを動かさないのがコツです。
○ 【ページの確認作業】についての補足
ScanSnapの「紙を引き込む力」は強いため、ページがくっついていると、薄い紙はぐちゃぐちゃになります。
そうしないためには、「糊がくっついていない場所を狙って切ればよい」ということになりますが、そうは簡単にいきません。
本によって、製本のきれいさが違います。糊が大量にはみ出している本もあるので、注意が必要です。
また、本の中央ぎりぎりまで情報が書いてあったりします。
そのため、ケース・バイ・ケースで対応していく必要があります。
白黒の本なら、紙がぐちゃぐちゃになっても、ScanSnapのソフトウェア側で、折れ目を消してくれます。しかし、カラーではそうはいきません。ここは、解体作業で、気を使うところです。
● 本の解体の仕方2(ハードカバーの単行本)
厚紙の表紙と背表紙が付いているハードカバーの単行本の場合は、【本の分割】の作業が若干違います。
以下、その方法を解説します。3以外の部分は、基本的に同じなので、省略します。
3【本の分割】.ハードカバーの単行本は、以下の方法で本を分割します。
3−1.表表紙の厚紙の根元を、カッターで切って取り除きます。
3−2.裏表紙の厚紙の根元を、カッターで切って取り除きます。
3−3.背表紙が手で引っ張って取れるようになるので、引っ張って取り除きます。
3−4.紐がある場合は、背表紙側に引っ張って、取り除きます。(そのまま残すと、細かな糸くずになり、スキャナの内部に散らばってしまいます)
3−5.床にカッター台を置きます。
3−6.表紙側から2ミリほどの位置で、本を割って開きます。
3−7.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意してください。
3−8.切り取った部分は斜めになっているので、綴じ部分を指で逆にひねって真っ直ぐにします。
3−9.裏表紙側から2ミリほどの位置で、本を割って開きます。
3−10.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意が必要です。
3−11.切り取った部分は斜めになっているので、綴じ部分を指で逆にひねって真っ直ぐにします。
3−12.残った部分を、何回かに分けて分割します。
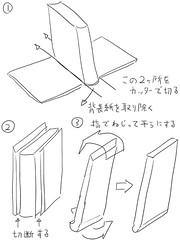
6〜11は、分かり難いと思いますので、補足説明を加えます。
ハードカバーの本の断面は、「( 」のように弧を描いています。この弧は、詳しく見ると、以下のような曲線になっています。
/
/
|
|
\
\
真ん中の方が平らで、端に行くほど反りが大きくなっています。なので、端の方だけ、薄く分割します。
/
--------<2mm程度で分割>
/
|
|
\
--------<2mm程度で分割>
\
そして、切り離した薄い部分を指で逆向きにひねって、真っ直ぐに矯正します。
|←平らにする
--------<分割>
/
|
|
\
--------<分割>
|←平らにする
これで、断裁機で綺麗に切れるようになります。そして、ScanSnapでも綺麗に取り込めるようになります。
● 断裁機を使う上での注意
断裁機を使う上で、私が失敗したことを書いておきます。
断裁機は、紙は切れますが、金属には弱いです。本にホッチキスなどがあり、その部分を誤って切ってしまうと刃が欠けます。
中綴じの本は、ホッチキスがあることが分かりやすいので、気をつければ避けられますが、平綴じの本で、針金で綴じられている場合は、見落として失敗してしまいます。
具体的には、以下のような構造です。太線の部分に、針金が入っています。
┌┰────
└┸────
こういった本は、教科書などに多いです。見落とさないように、気をつけてください。
さて、誤って刃をかけさせてしまった場合ですが、一応本は切れます。
ただし、下の方の数ページが切れなかったりします。その場合は、本の下に新聞紙を敷いて、底上げをして裁断するとよいです。
またその際、毎回新聞紙を切る必要はないです。新聞紙をセロテープで固定しておき、その上に本を置けばよいです。それだけで、綺麗に切れるようになります。
● 本の解体補足
本は、10〜20冊ほど解体して、ストックを作っておいて、スキャン作業を行いました。
あまり大量に解体しておくと、山が崩れた時に、ページの順番を修復できなくなりますので。
また、籠の中に入れて、崩れにくいようにしておきました。
● スキャン前の設定
さて、本の解体の説明が終わったので、次はスキャンの説明です。
スキャンは、ScanSnapを使います。取り込んだファイルは自動でPDF化してくれます。そして、OCRもしてくれます。
ただし、OCRは時間がかかります。このOCRは、後でまとめて行うこともできるので、寝ている間に行うとよいです。無駄な時間は極力省いた方がよいです。
また、本の種類によって、選ぶ設定が若干異なります。ScanSnapでは、10個までの設定を登録できますので、予め以下の設定を登録しておき、用途に応じて選択するとよいです。
設定ウィンドウは、タスクトレイにある「青丸にS」のアイコンをダブルクリックすると表示されます。


作製した設定は、設定ウィンドウの[読み取り設定]のメニュー内から、登録・管理することができます。
それでは、以下、私が用途に応じて作製した設定です。
○ 0.共通部分
全部の設定に共通する部分です。各設定は、共通しない部分だけを書いていきます。
・アプリ選択
アプリケーションの選択:指定したフォルダに保存
・保存先
イメージの保存先:〜\scan(パスは任意に設定してください)
ファイル名の設定:「日付を使用します」
・読み取りモード
読み取り面の選択:両面読み取り
・ファイル形式
ファイル形式の選択:PDF
テキスト認識の選択:「検索可能なPDFにします」をOFF
・原稿
原稿サイズの選択:サイズ自動検出
マルチフィード検出:重なりで検出(超音波)
・ファイルサイズ
圧縮率:3
○ 1.グレー文
文字中心の書籍用の設定です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
「文字列の傾きを自動的に補正します」をON
その他は全てOFF
○ 2.グレー文(傾き補正なし)
「グレー文」から、「文字列の傾きを自動的に補正します」を解除しています。これは、図版が入っている本用の設定です。
図版が入っていると、その図に引きずられて、傾き補正で、ページが変な方向に曲がったりするためです。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
その他は全てOFF
○ 3.グレー絵(傾き補正なし)
「グレー文」から、さらに「文字をくっきしりします」を解除しています。これは、写真中心の本用の設定です。
写真が多い場合、「文字をくっきしりします」をONにしていると、写真が黒くなりすぎるので、その対策です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
その他は全てOFF
○ 4.カラー絵(傾き補正なし)
「グレー絵(傾き補正なし)」のカラー版です。
カラー本は、だいたい図版中心なので、「文字列の傾きを自動的に補正します」はOFFにしています。
この設定では、通常の本より、若干色が薄くなりますが、あまり気にしないようにしています。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
その他は全てOFF
○ 5.カラー文
「グレー文」のカラー版です。
参考書などに多い、文字の一部が色つきになっている本向けの設定です。「カラー絵」と違い、「文字をくっきしりします」をONにしています。
この設定では、実際の色とは違い、色身が強調されますが、図版が多くなければ気になりません。文字優先で読みやすくしたい場合の設定です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
「文字をくっきしりします」をON
「文字列の傾きを自動的に補正します」をON
その他は全てOFF
○ 6.カラー文(傾き補正なし)
「カラー文」から、「文字列の傾きを自動的に補正します」をOFFにしたものです。
図版の多い参考書などに使います。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
「文字をくっきしりします」をON
その他は全てOFF
○ 7.マンガ
マンガ用の設定です。スクリーントーンを潰さずに取り込むために、600dpiにしています。また、マンガの線に引きずられないように、「文字列の傾きを自動的に補正します」をOFFにしています。
絵の資料ではなく、話だけ分かればよいマンガは「グレー文(傾き補正なし)」で取り込んでいます。
・読み取りモード
画質の選択:エクセレント(カラー/グレー:600dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
その他は全てOFF
設定は以上です。これらの設定を、用途によって切り換えて使用していきます。
● スキャンの設定の切り替え
タスクトレイにある「青丸にS」のアイコンを左クリックすれば切り替えられます。
● 表紙のスキャンについて
スキャンしたページは、後でAcrobatで向きを変更できます。なので、表紙は、縦向きでも横向きでも構わずスキャンしてください。
最初の頃は、表紙だけフラット・スキャナでスキャンして、あとで結合していましたが、表紙もScanSnapで取り込んだ方が早いし便利です。これは、後悔しています。
● スキャナの掃除
ScanSnapは、かなり頻繁に掃除しなければなりません。なぜならば、細かな紙くずが、すぐに内部に充満するからです。
本体は、簡単に蓋を開けて掃除できるようになっています。
掃除は、眼鏡拭きがあるとよいです。また、眼鏡拭きでなくても、目が細かく、ガラス(スキャン面)を傷付けないものなら、何でもよいです。
液体系で拭くのは避けた方がよいです。内部には、電子部品とともに、ゴムの部品もあります。水もエタノールも避けた方が無難です。
また、スキャン面のガラス窓に、本の糊が付着することがあります。その場合は、ゴシゴシとこすって取り除いてください。そのままにしていると、全ての画像に縦線が入ります。

● カラー画像取り込み時の注意
ScanSnapは、グレーでの本の取り込みは、ほとんど無敵に近いです。ただ取り込むだけでなく、紙焼けを消したり、折れ目を消したりもしてくれます。エラーもほとんどないです。
しかしこのScanSnapも、カラーの取り込みには弱いです。
特に、光沢紙の取り込みには弱く、静電気のせいか、スキャン面にゴミが付きやすく、スキャン後の画像に縦線が入りやすいです。
カラー画像を取り込む場合は、10ページずつぐらいにして、スキャン後に頻繁に確認して、必要に応じて内部の掃除をするようにしなければなりません。
特に、黒背景のページでは、ほぼ何らかのエラーが出ると思っていた方がよいです。
● スキャナの上と下の特性の違い
両面同時にスキャンしてくれるScanSnapには、上側と下側に2つのスキャン窓が付いています。
この2つのスキャナには、実は精度に違いがあります。これは、電子的な性能の違いではなく、構造的な問題です。
紙をカーブさせながら取り込みスキャンするため、紙がスキャナの間を通るときの角度が、上と下では若干違います。
そのため、黒背景のカラー画像の時に、下側のスキャナでは紙の端が白くぼける現象が発生します。
黒背景のページをスキャンする場合は、上側のスキャナを使うようにした方がよいです。
では、具体的な作業をどうするかと言うと、表から1回、裏から1回スキャンしておき、あとでAcrobatで合成するのがよいです。
Acrobatでは、各ページやファイルを、ドラッグ&ドロップで編集することができます。
● 分割してスキャンした本の結合
ScanSnapには、Adobe Acrobatが同梱されています。このAcrobatを使って、ドラッグ&ドロップで簡単に編集を行うことができます。
とりあえずガンガンスキャンしておき、1冊分取り込んだ時点で結合して、本のタイトルをファイル名にするとよいです。
スキャンには、エラーがたまにありますので、1冊ごとに確認しておいた方がよいです。
ちなみに、起こるエラーとしては、ページの二重取り込みはまずないです。
ただし、しおりが挟まったまま取り込まれることはたまにあります。
あとは、ページの大きさを判断ミスして、巨大な画像になっている場合も稀にですがあります。
● 消耗品の交換
500冊ぐらいスキャンしたところで、ページ分離用の部品を交換する必要があります。ゴムが磨り減ってしまうからです。

私は、この部品交換のタイミングに気付かずに、かなり四苦八苦しました。交換しないと、読み取りエラーが頻発します。
部品は2,000円ぐらいしますが、消耗品として割り切るしかないです。
あと、もっと大量にスキャンすると、ローラーも替える必要が出てきます。
● OCR
スキャンしたあとのPDFは、ScanSnap付属のソフト「ScanSnap Organizer」で、まとめてOCRができます。
けっこう時間がかかるので、寝ている間にするとよいです。
この「ScanSnap Organizer」ですが、ScanSnapでスキャンしたPDFしかスキャンできないようになっています。
しかし、他のPDFであっても、ScanSnapでスキャンしたページをそのPDFに加えれば、OCR可能になります。
「ScanSnap Organizer」のOCR精度は、Acrobatの精度よりも遥かに高いです。また、日本語、英語などと言語が選べますので、スキャンした本によって、言語を切り替えるとよいです。
あと、プログラム系の書籍は、OCRが上手くいかないものと思っておいた方がよいです。日本語と英語の混在している紙面になりますので。どちらかの言語を犠牲にしなければいけません。
● PDFファイルとAcrobatの設定
見開き表示にした際、縦書きの本で、若いページを右側にしたい場合は、以下のような設定にします。
1.Adobe Acrobatの[ファイル]→[プロパティ]で、「文書のプロパティ」ダイアログを表示します。
2.[詳細設定]タブを選び、[読み上げオプション]→[綴じ方]→[右]に設定します。
これで、縦書きの本も見開きで見られるようになります。
ちなみに、見開き表示は、以下の方法でできます。
1.Adobe Acrobatのメニュー[表示]→[ページ表示]→[見開きページ]を選択します。
また、見開きページにした際、1ページ目を表紙にして、2ページ目から見開きにするには、以下のような設定にします。
1.Adobe Acrobatのメニュー[表示]→[ページ表示]→[見開きページモードでページをレイアウト]をチェックします。
● 整理と閲覧
取り込んだPDFは、Explorerのフォルダでジャンル分けしています。また、スキャン日やページ数などの情報を、エクセルファイルでまとめています。
また、PDFですが、1ページ目を画像にして、同じフォルダに保存しています。
なぜそういったことをしているかと言うと、PDF管理ソフトではなく、画像ビューワーで本を探せるようにするためです。
いくつかのサムネール付きのPDF管理ソフトを試してみたのですが、どうも速度が遅く、使い勝手が悪かったです。なので、画像ビューワーで表紙を見て、PDFにアクセスする方式にしました。
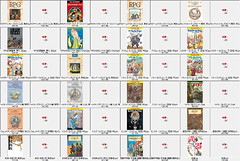
● バックアップ
ハードディスク2台に保存した上に、DVD2枚に保存して、4重に保存するようにしました。
よほどのことがない限り、これで十分かと思います。
スキャンした本は全部捨てました。本は、紙ゴミの日以外にも、地区センターの紙ゴミ用のボックスに出しに行きました。
● まとめ
本の電子化は、やり方次第で、かかる時間がかなり違います。
最初の段階で、最後の方法が確立できていれば、たぶん1/4ぐらいの時間で全てが終わったと思います。
なぜなら、1日あたりのスキャン冊数が、最大で5倍ぐらい違っていましたので。
というわけで、これからスキャンする人の参考になればと思います。
スキャンしたページ数は18万7174ページ。電子化した本や冊子、書類などの点数は900点です。
1点あたりのページ数は208ページなので、ほぼ900冊の本をスキャンしたと言ってよいでしょう。
かけた日数は48日。仕事をしながらの作業でしたので、正確には何時間か分かりません。
この作業ですが、最初の頃と最後の頃では、その効率が圧倒的に違っていました。
そこで、この経験を通して、最短で作業を進められる方法を、マニュアル化しておこうと思います。
同じように本の電子化をする人が、一から方法を模索するのは馬鹿らしいですので。
今回の一件を、マンガでも書きました。そちらは下記を参考にしてください。
□創活ノート 第14話「本の電子化」
https://codezine.jp/article/detail/4963
● 用意する道具
用意する道具ですが、以下のものを準備しました。最初の2つだけ購入しています。残りは、部屋にあったものを、そのまま利用しています。
・ドキュメント・スキャナ「FUJITSU ScanSnap S1500 FI-S1500」(Amazon価格:¥37,300)
 |
・手動断裁機「プラス 断裁機 裁断幅A4 PK-513L 26-106」(Amazon価格:¥31,730)
 |
・ディスク・カッター「ディスクカッター・ライト DC-100」(Amazon価格:¥2,436)
 |
・カッター「L型カッター L-550P L-550P」(Amazon価格:¥326)
 |
・カッター台
・金定規
● 道具についての解説1
○ ドキュメント・スキャナ
これがないと始まりません。本をスキャンして電子化してくれます。使い方や設定の詳細は後述します。
○ 手動断裁機
高価なものを買いましたが、中国製の安いものでも十分だと思います。少々斜めに裁断されても、ScanSnapで補正されますので。
あと、手動断裁機は、替えの刃が高価です。替えの刃の値段(15,000円)だけで、中国製の安い断裁機が買えます。そういう意味でも、安いもので済ましてもよいと思います。
○ ディスク・カッター
表紙をカットするのに使いました。普通のカッターで代用しても構いません。家にあったので、便利に使いました。
○ カッター
割と大きめの物を使っています。なぜならば、カッターは背表紙の解体用に使うからです。なので、小さいカッターだと怪我をします。大きめの、しっかりと握れるカッターがよいです。
○ カッター台
上述の、背表紙の解体の時に利用します。
○ 金定規
上述の、背表紙の解体の時に利用します。
ただし、慣れてくると、定規なしで、背表紙をきれいに解体できるようになるので、なくてもよいです。
● 道具についての解説2
本の電子化の記事でよく紹介されているけど、実際には使わなかったものです。
○ グルーガン
熱で接着剤を溶かして、背表紙をはがしやすくするためのものです。なくても困りません。
本のページの横幅を揃えたいという几帳面な人は、あった方がよいかもしれません。でも、電子化すると、そういったことは気にならないので必要ないです。
また、解体した本を再度修復するつもりがあれば必要だと思います。そういった目的がなければ、この道具は必要ありません。
● 本の解体の仕方1(文庫、平綴じ本)
本は、効率よく、かつ、スキャンしやすいように解体するのがポイントです。
以下、その手順を書きます。本の中のハガキや広告は、あらかじめ除いておいてください。
1.表紙を取ります。
2.表紙を、表表紙と背表紙の間で、ディスクカッターでカットします。大型の本は、表紙の耳の部分もディスクカッターでカットします。
3【本の分割】.本の厚さが、断裁機を通らない場合は、以下の方法で本を分割します。
3−1.床にカッター台を置きます。
3−2.本を割って開きます。
3−3.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意が必要です。
3−4.紐がある場合は、背表紙側に引っ張って、取り除きます。(そのまま残すと、細かな糸くずになり、スキャナの内部に散らばってしまいます)
4.本を、断裁機で、背表紙側を数ミリ裁断します。
5【ページの確認作業】.ページが正しく断裁されているかの確認作業を行います。
5−1.切った側とは逆の位置を持ち、扇状に紙を広げます。
5−2.変なしなり方をしている場所があれば、糊でページがくっついているので、ページとページを手で切り離します。
5−3.扇状になった場所の上を指でなぞり、硬い部分があれば、糊でページがくっついているので、ページとページを手で切り離します。
5−4.何度かこの作業を行い、くっついている部分がなければ確認作業終了です。
5−5.大切な本の場合は、指で1枚ずつ分離して、きちんと離れているか確認します。
○ 【本の分割】についての補足
最初のうちは、金定規を当てた方がよいと思います。慣れれば、金定規なしでも、簡単に切り離せるようになります。
また、本によっては、数ページずつ中綴じされていて、それが糊でくっついています。そのため、開くページによって、切り離しやすさが違います。
本にもよりますが、糊が少ない場合は、糊だけでくっついているページの境目を狙うと切りやすいです。逆に糊が多い場合は、そこは避けた方がよいです。
どちらにしろ、あまり強くカッターを動かさないのがコツです。
○ 【ページの確認作業】についての補足
ScanSnapの「紙を引き込む力」は強いため、ページがくっついていると、薄い紙はぐちゃぐちゃになります。
そうしないためには、「糊がくっついていない場所を狙って切ればよい」ということになりますが、そうは簡単にいきません。
本によって、製本のきれいさが違います。糊が大量にはみ出している本もあるので、注意が必要です。
また、本の中央ぎりぎりまで情報が書いてあったりします。
そのため、ケース・バイ・ケースで対応していく必要があります。
白黒の本なら、紙がぐちゃぐちゃになっても、ScanSnapのソフトウェア側で、折れ目を消してくれます。しかし、カラーではそうはいきません。ここは、解体作業で、気を使うところです。
● 本の解体の仕方2(ハードカバーの単行本)
厚紙の表紙と背表紙が付いているハードカバーの単行本の場合は、【本の分割】の作業が若干違います。
以下、その方法を解説します。3以外の部分は、基本的に同じなので、省略します。
3【本の分割】.ハードカバーの単行本は、以下の方法で本を分割します。
3−1.表表紙の厚紙の根元を、カッターで切って取り除きます。
3−2.裏表紙の厚紙の根元を、カッターで切って取り除きます。
3−3.背表紙が手で引っ張って取れるようになるので、引っ張って取り除きます。
3−4.紐がある場合は、背表紙側に引っ張って、取り除きます。(そのまま残すと、細かな糸くずになり、スキャナの内部に散らばってしまいます)
3−5.床にカッター台を置きます。
3−6.表紙側から2ミリほどの位置で、本を割って開きます。
3−7.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意してください。
3−8.切り取った部分は斜めになっているので、綴じ部分を指で逆にひねって真っ直ぐにします。
3−9.裏表紙側から2ミリほどの位置で、本を割って開きます。
3−10.割ったページの間にカッターの刃を置き、軽く何度か上下させます。この時、強く上下させると、滑って関係ない場所を切るので注意が必要です。
3−11.切り取った部分は斜めになっているので、綴じ部分を指で逆にひねって真っ直ぐにします。
3−12.残った部分を、何回かに分けて分割します。
6〜11は、分かり難いと思いますので、補足説明を加えます。
ハードカバーの本の断面は、「( 」のように弧を描いています。この弧は、詳しく見ると、以下のような曲線になっています。
/
/
|
|
\
\
真ん中の方が平らで、端に行くほど反りが大きくなっています。なので、端の方だけ、薄く分割します。
/
--------<2mm程度で分割>
/
|
|
\
--------<2mm程度で分割>
\
そして、切り離した薄い部分を指で逆向きにひねって、真っ直ぐに矯正します。
|←平らにする
--------<分割>
/
|
|
\
--------<分割>
|←平らにする
これで、断裁機で綺麗に切れるようになります。そして、ScanSnapでも綺麗に取り込めるようになります。
● 断裁機を使う上での注意
断裁機を使う上で、私が失敗したことを書いておきます。
断裁機は、紙は切れますが、金属には弱いです。本にホッチキスなどがあり、その部分を誤って切ってしまうと刃が欠けます。
中綴じの本は、ホッチキスがあることが分かりやすいので、気をつければ避けられますが、平綴じの本で、針金で綴じられている場合は、見落として失敗してしまいます。
具体的には、以下のような構造です。太線の部分に、針金が入っています。
┌┰────
└┸────
こういった本は、教科書などに多いです。見落とさないように、気をつけてください。
さて、誤って刃をかけさせてしまった場合ですが、一応本は切れます。
ただし、下の方の数ページが切れなかったりします。その場合は、本の下に新聞紙を敷いて、底上げをして裁断するとよいです。
またその際、毎回新聞紙を切る必要はないです。新聞紙をセロテープで固定しておき、その上に本を置けばよいです。それだけで、綺麗に切れるようになります。
● 本の解体補足
本は、10〜20冊ほど解体して、ストックを作っておいて、スキャン作業を行いました。
あまり大量に解体しておくと、山が崩れた時に、ページの順番を修復できなくなりますので。
また、籠の中に入れて、崩れにくいようにしておきました。
● スキャン前の設定
さて、本の解体の説明が終わったので、次はスキャンの説明です。
スキャンは、ScanSnapを使います。取り込んだファイルは自動でPDF化してくれます。そして、OCRもしてくれます。
ただし、OCRは時間がかかります。このOCRは、後でまとめて行うこともできるので、寝ている間に行うとよいです。無駄な時間は極力省いた方がよいです。
また、本の種類によって、選ぶ設定が若干異なります。ScanSnapでは、10個までの設定を登録できますので、予め以下の設定を登録しておき、用途に応じて選択するとよいです。
設定ウィンドウは、タスクトレイにある「青丸にS」のアイコンをダブルクリックすると表示されます。
作製した設定は、設定ウィンドウの[読み取り設定]のメニュー内から、登録・管理することができます。
それでは、以下、私が用途に応じて作製した設定です。
○ 0.共通部分
全部の設定に共通する部分です。各設定は、共通しない部分だけを書いていきます。
・アプリ選択
アプリケーションの選択:指定したフォルダに保存
・保存先
イメージの保存先:〜\scan(パスは任意に設定してください)
ファイル名の設定:「日付を使用します」
・読み取りモード
読み取り面の選択:両面読み取り
・ファイル形式
ファイル形式の選択:PDF
テキスト認識の選択:「検索可能なPDFにします」をOFF
・原稿
原稿サイズの選択:サイズ自動検出
マルチフィード検出:重なりで検出(超音波)
・ファイルサイズ
圧縮率:3
○ 1.グレー文
文字中心の書籍用の設定です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
「文字列の傾きを自動的に補正します」をON
その他は全てOFF
○ 2.グレー文(傾き補正なし)
「グレー文」から、「文字列の傾きを自動的に補正します」を解除しています。これは、図版が入っている本用の設定です。
図版が入っていると、その図に引きずられて、傾き補正で、ページが変な方向に曲がったりするためです。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
その他は全てOFF
○ 3.グレー絵(傾き補正なし)
「グレー文」から、さらに「文字をくっきしりします」を解除しています。これは、写真中心の本用の設定です。
写真が多い場合、「文字をくっきしりします」をONにしていると、写真が黒くなりすぎるので、その対策です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:グレー
オプション
その他は全てOFF
○ 4.カラー絵(傾き補正なし)
「グレー絵(傾き補正なし)」のカラー版です。
カラー本は、だいたい図版中心なので、「文字列の傾きを自動的に補正します」はOFFにしています。
この設定では、通常の本より、若干色が薄くなりますが、あまり気にしないようにしています。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
その他は全てOFF
○ 5.カラー文
「グレー文」のカラー版です。
参考書などに多い、文字の一部が色つきになっている本向けの設定です。「カラー絵」と違い、「文字をくっきしりします」をONにしています。
この設定では、実際の色とは違い、色身が強調されますが、図版が多くなければ気になりません。文字優先で読みやすくしたい場合の設定です。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
「文字をくっきしりします」をON
「文字列の傾きを自動的に補正します」をON
その他は全てOFF
○ 6.カラー文(傾き補正なし)
「カラー文」から、「文字列の傾きを自動的に補正します」をOFFにしたものです。
図版の多い参考書などに使います。
・読み取りモード
画質の選択:スーパーファイン(カラー/グレー:300dpi)
カラーモードの選択:カラー
オプション
「文字をくっきしりします」をON
その他は全てOFF
○ 7.マンガ
マンガ用の設定です。スクリーントーンを潰さずに取り込むために、600dpiにしています。また、マンガの線に引きずられないように、「文字列の傾きを自動的に補正します」をOFFにしています。
絵の資料ではなく、話だけ分かればよいマンガは「グレー文(傾き補正なし)」で取り込んでいます。
・読み取りモード
画質の選択:エクセレント(カラー/グレー:600dpi)
カラーモードの選択:グレー
オプション
「文字をくっきしりします」をON
その他は全てOFF
設定は以上です。これらの設定を、用途によって切り換えて使用していきます。
● スキャンの設定の切り替え
タスクトレイにある「青丸にS」のアイコンを左クリックすれば切り替えられます。
● 表紙のスキャンについて
スキャンしたページは、後でAcrobatで向きを変更できます。なので、表紙は、縦向きでも横向きでも構わずスキャンしてください。
最初の頃は、表紙だけフラット・スキャナでスキャンして、あとで結合していましたが、表紙もScanSnapで取り込んだ方が早いし便利です。これは、後悔しています。
● スキャナの掃除
ScanSnapは、かなり頻繁に掃除しなければなりません。なぜならば、細かな紙くずが、すぐに内部に充満するからです。
本体は、簡単に蓋を開けて掃除できるようになっています。
掃除は、眼鏡拭きがあるとよいです。また、眼鏡拭きでなくても、目が細かく、ガラス(スキャン面)を傷付けないものなら、何でもよいです。
液体系で拭くのは避けた方がよいです。内部には、電子部品とともに、ゴムの部品もあります。水もエタノールも避けた方が無難です。
また、スキャン面のガラス窓に、本の糊が付着することがあります。その場合は、ゴシゴシとこすって取り除いてください。そのままにしていると、全ての画像に縦線が入ります。
● カラー画像取り込み時の注意
ScanSnapは、グレーでの本の取り込みは、ほとんど無敵に近いです。ただ取り込むだけでなく、紙焼けを消したり、折れ目を消したりもしてくれます。エラーもほとんどないです。
しかしこのScanSnapも、カラーの取り込みには弱いです。
特に、光沢紙の取り込みには弱く、静電気のせいか、スキャン面にゴミが付きやすく、スキャン後の画像に縦線が入りやすいです。
カラー画像を取り込む場合は、10ページずつぐらいにして、スキャン後に頻繁に確認して、必要に応じて内部の掃除をするようにしなければなりません。
特に、黒背景のページでは、ほぼ何らかのエラーが出ると思っていた方がよいです。
● スキャナの上と下の特性の違い
両面同時にスキャンしてくれるScanSnapには、上側と下側に2つのスキャン窓が付いています。
この2つのスキャナには、実は精度に違いがあります。これは、電子的な性能の違いではなく、構造的な問題です。
紙をカーブさせながら取り込みスキャンするため、紙がスキャナの間を通るときの角度が、上と下では若干違います。
そのため、黒背景のカラー画像の時に、下側のスキャナでは紙の端が白くぼける現象が発生します。
黒背景のページをスキャンする場合は、上側のスキャナを使うようにした方がよいです。
では、具体的な作業をどうするかと言うと、表から1回、裏から1回スキャンしておき、あとでAcrobatで合成するのがよいです。
Acrobatでは、各ページやファイルを、ドラッグ&ドロップで編集することができます。
● 分割してスキャンした本の結合
ScanSnapには、Adobe Acrobatが同梱されています。このAcrobatを使って、ドラッグ&ドロップで簡単に編集を行うことができます。
とりあえずガンガンスキャンしておき、1冊分取り込んだ時点で結合して、本のタイトルをファイル名にするとよいです。
スキャンには、エラーがたまにありますので、1冊ごとに確認しておいた方がよいです。
ちなみに、起こるエラーとしては、ページの二重取り込みはまずないです。
ただし、しおりが挟まったまま取り込まれることはたまにあります。
あとは、ページの大きさを判断ミスして、巨大な画像になっている場合も稀にですがあります。
● 消耗品の交換
500冊ぐらいスキャンしたところで、ページ分離用の部品を交換する必要があります。ゴムが磨り減ってしまうからです。
私は、この部品交換のタイミングに気付かずに、かなり四苦八苦しました。交換しないと、読み取りエラーが頻発します。
部品は2,000円ぐらいしますが、消耗品として割り切るしかないです。
 |
あと、もっと大量にスキャンすると、ローラーも替える必要が出てきます。
 |
● OCR
スキャンしたあとのPDFは、ScanSnap付属のソフト「ScanSnap Organizer」で、まとめてOCRができます。
けっこう時間がかかるので、寝ている間にするとよいです。
この「ScanSnap Organizer」ですが、ScanSnapでスキャンしたPDFしかスキャンできないようになっています。
しかし、他のPDFであっても、ScanSnapでスキャンしたページをそのPDFに加えれば、OCR可能になります。
「ScanSnap Organizer」のOCR精度は、Acrobatの精度よりも遥かに高いです。また、日本語、英語などと言語が選べますので、スキャンした本によって、言語を切り替えるとよいです。
あと、プログラム系の書籍は、OCRが上手くいかないものと思っておいた方がよいです。日本語と英語の混在している紙面になりますので。どちらかの言語を犠牲にしなければいけません。
● PDFファイルとAcrobatの設定
見開き表示にした際、縦書きの本で、若いページを右側にしたい場合は、以下のような設定にします。
1.Adobe Acrobatの[ファイル]→[プロパティ]で、「文書のプロパティ」ダイアログを表示します。
2.[詳細設定]タブを選び、[読み上げオプション]→[綴じ方]→[右]に設定します。
これで、縦書きの本も見開きで見られるようになります。
ちなみに、見開き表示は、以下の方法でできます。
1.Adobe Acrobatのメニュー[表示]→[ページ表示]→[見開きページ]を選択します。
また、見開きページにした際、1ページ目を表紙にして、2ページ目から見開きにするには、以下のような設定にします。
1.Adobe Acrobatのメニュー[表示]→[ページ表示]→[見開きページモードでページをレイアウト]をチェックします。
● 整理と閲覧
取り込んだPDFは、Explorerのフォルダでジャンル分けしています。また、スキャン日やページ数などの情報を、エクセルファイルでまとめています。
また、PDFですが、1ページ目を画像にして、同じフォルダに保存しています。
なぜそういったことをしているかと言うと、PDF管理ソフトではなく、画像ビューワーで本を探せるようにするためです。
いくつかのサムネール付きのPDF管理ソフトを試してみたのですが、どうも速度が遅く、使い勝手が悪かったです。なので、画像ビューワーで表紙を見て、PDFにアクセスする方式にしました。
● バックアップ
ハードディスク2台に保存した上に、DVD2枚に保存して、4重に保存するようにしました。
よほどのことがない限り、これで十分かと思います。
スキャンした本は全部捨てました。本は、紙ゴミの日以外にも、地区センターの紙ゴミ用のボックスに出しに行きました。
● まとめ
本の電子化は、やり方次第で、かかる時間がかなり違います。
最初の段階で、最後の方法が確立できていれば、たぶん1/4ぐらいの時間で全てが終わったと思います。
なぜなら、1日あたりのスキャン冊数が、最大で5倍ぐらい違っていましたので。
というわけで、これからスキャンする人の参考になればと思います。
1つ前の記事:[EX リバーシ] 「ウサギ」ステージ
1つ後の記事:創活ノート 第14話「本の電子化」













